



by: Michael Santucci
CEO & Founder: Engineering Consultants Group, Inc.
(Equipment Monitoring & Diagnostics, Plant Controls Engineering, Predictive Analytics, Evidence-Based Diagnostic Reasoning)

Introduction
Predictive maintenance has evolved significantly over the years, transforming from a reactive approach to a sophisticated and data-driven strategy. A strategy that leverages advanced data analytics, machine learning techniques, and data models to predict when equipment or assets are likely to experience failures. Most predictive models today rely on historical data to identify patterns, trends, and anomalies associated with past equipment failures. This analysis helps the model learn the normal behavior of the equipment and detect deviations that may signify potential issues. However, the start of building an accurate model is collecting “good” historical data to train it. As one can imagine, collecting quality and adequate data can be challenging. Data is often missing for many reasons. This is where data imputation becomes essential in this process. It is a technique used to handle missing or incomplete data in datasets. Here we will explore the various types of missing data, the popular methods of data imputation in predictive maintenance, the strengths and challenges of each method, and the art of selecting the right data imputation method or combination. We will also take you through ECG’s Predict-It’s journey and method of data imputation which differentiates it from many of the solutions in the market today.
Types of Missing Data and Implications to Predictive Maintenance Models
Predictive maintenance models rely heavily on historical data to identify patterns and trends that can signal potential equipment failures. Missing data leads to biased models, inaccurate predictions, overlooking early signs, and introduces uncertainties, which leads to the end users’ lack of confidence in the decision outputs and the effectiveness of maintenance models. The implications of missing data in predictive maintenance models are far-reaching, affecting model accuracy, reliability, operational efficiency, and decision-making processes. Further, in the world of industrial operations, data may be compromised due to sensor malfunctions, communication errors, or other issues.
There are three main classifications of missing data to understand when it comes to defining the right data imputation solution. The first type is Data Missing Altogether. This is where the entire data points for specific variables are missing. An example of this is when a sensor malfunction occurs and leads to a complete loss of data for a particular equipment parameter over a specific period. Since there is none to very limited historical data that can be used as references, data imputation’s capacity to impute missing data is limited in this scenario. The second classification is Data Missing Not at Random. This is the absence of data related to specific conditions or patterns. In this example, data is missing for equipment temperature during extreme environmental conditions (e.g., very high or low temperatures), where sensors may fail to operate reliably. The last category is Data Missing at Random. Here the missing data occurs randomly and is unrelated to any specific condition. An example is data from a vibration sensor occasionally fails to record due to random and unpredictable communication issues, resulting in sporadic missing values.
Chart 1: Examples of Data Missing at Random.
Below is a graph of three variables with random missing data, indicated with red asterisks.
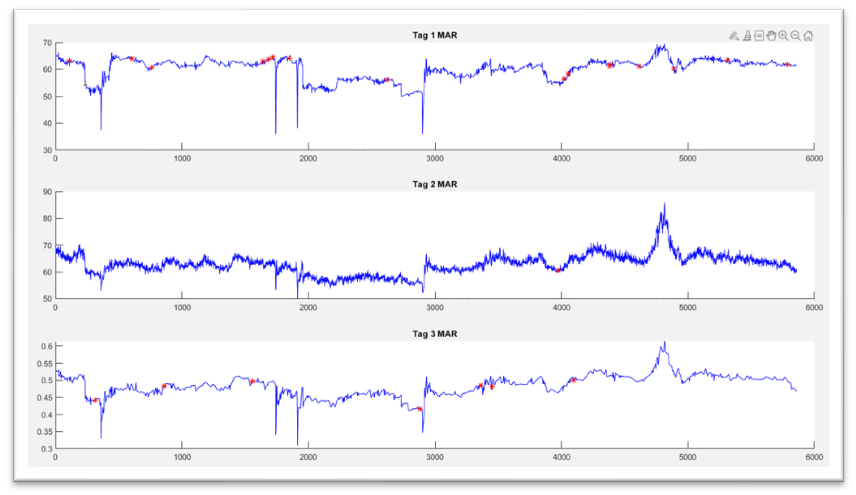
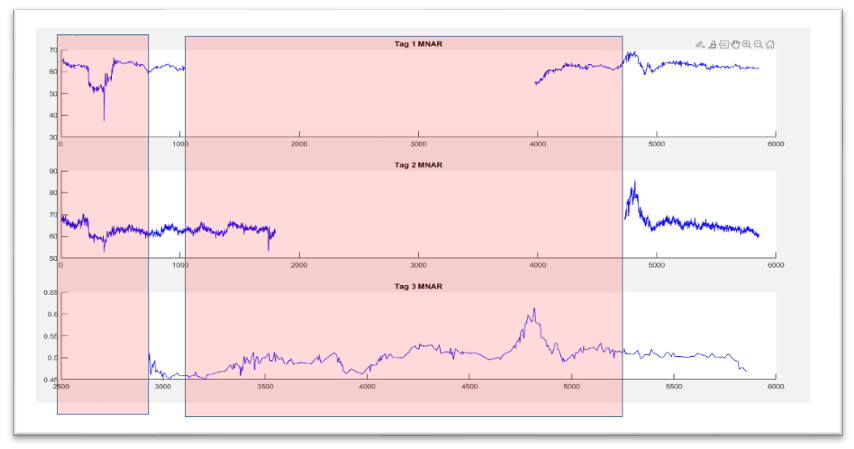
Chart 2: Examples of Data Missing Not at Random.
The graph below is a graph of three variables where the data is missing for a long period.
Understanding these types and causes of missing data is essential for developing effective data imputation strategies in predictive maintenance. Addressing these challenges ensures that the models are trained on complete and representative datasets, leading to more accurate predictions and reliable maintenance strategies.
Challenges in Filling Missing Data for Predictive Maintenance
Before we go through the various types of data imputation methods, it’s important to understand some of the common challenges of filling missing data. Choosing the right data imputation approach requires careful evaluation to retain the equipment’s behavior. It’s a process and heuristic balance of preserving correlation, probability density, and the ability to tolerate outliers and extrapolate data without compromising certainty. In the first challenge, preserving correlation, it’s important to maintain the relationship between variables. This ensures that relationships between variables remain intact, and allows for an accurate representation of the real patterns in the data. Imputation methods should also be robust to outliers that might be present in the data. Outliers are sometimes indicators of unexpected malfunctions, environmental disturbances, or other rare events which is important to maintain as it can lead to indicators of issues that need to be addressed. Another aspect of preserving data originality is not altering the original probability density which represents the likelihood of different values occurring in the dataset. Preserving this ensures that imputed values accurately reflect the statistical properties of the original data. This of course leads to more accurate and meaningful analyses. Lastly, when performing data imputation it’s important to be able to extrapolate outside the observed data range without introducing excessive uncertainty. If imputation methods are not capable of extrapolating, extreme values may be underestimating or overestimating, which typically leads to biased results. Extrapolation should be used when it is safe which is decided by analyzing the correlation structure of the data. So the ability to extrapolate can help in providing more accurate estimates for values that are beyond the observed range, hence reducing bias in imputed data but only when it is appropriate. All these challenges make the task of data imputation a complicated and sensitive one which requires a very heuristic and well-balanced approach.
Various Methods for Data Imputation in Predictive Maintenance
We now get into the various methods used for data imputation in predictive maintenance. Some of the well-known ones include K-Nearest Neighbors (KNN), Probabilistic Principal Component Analysis (PPCA), Multiple Imputation by Chained Equation (MICE), mean imputation, regression, random forest-based, and others. Each of these has its strengths, limitations, and suitability depending on their different use cases and types of missing data. Following is a brief introduction to each of these common methods.
One of the most common methods is K-Nearest Neighbors commonly known as KNN. It imputes missing values based on the majority class or average of the K-nearest data points in a common feature class. The benefit of the KNN method is that it is easy to understand and implement, making it a user-friendly solution. It also is non-parametric which means it doesn’t assume a specific data distribution therefore allowing more flexibility. It is also well-suited for capturing local patterns in a data set. The drawback is that it is not known for handling outlier data and potentially affecting imputation accuracy.
Another known data imputation method is Probabilistic Principal Component Analysis (PPCA). It is an expectation-maximization algorithm used to impute missing values where it tries to estimate the underlying structure of the data. This method is known for its effective ability to handle high-dimensional data and preserve data correlations. However, the approach it uses assumes a linear relationship between variables which can sometimes be intensive, especially for large datasets.
Lastly, the Multiple Imputation by Chained Equation (MICE) is an iterative method that imputes missing values by modeling each variable with missing data conditional on the others. It’s been found to be flexible to various types of missing data and can be accommodating to different patterns. Because it models each variable conditionally, it can preserve inter-variable relationships but with it comes various convergence issues. As one can see, there are many data imputation methods, each with its strengths and shortcomings. Selecting a method or combination of methods requires a delicate approach and balance to ensure the integrity of the system’s behavior is not altered or biased.
The Heuristic Approach
As was previously noted, creating an appropriate data imputation technique for a predictive maintenance solution requires balancing and making trade-offs between several different factors, particularly when it comes to supporting an environment that involves real-time activities. The first step is choosing an algorithm that can deliver a certain level of accuracy without changing the equipment’s behavior as it is. Accuracy is often associated with a cost of resources to execute the computation, which also influences time-to-compute. In a Monitoring and Diagnostic (M&D) environment, where decisions and actions have to be made rapidly, users cannot afford to wait hours for the system to run models. This translates into a demand for strong system availability, dependability, and stability. Other variables to consider include user flexibility and ease of usage. End users should be able to choose when and for what data to employ imputation. All of these “-ilities” (usability, availability, stability, dependability, adaptability, etc.) and data accuracy necessitate a true heuristic approach because it is a balancing of all of these elements to ensure end-users in a fast-paced environment have the data they need to make quick but data-driven decisions.
Predict-It’s Data Imputation Journey
For decades, ECG has been engineering predictive maintenance solutions for heavy industrial operations across the globe. Providing operators with insights into the state and health of their equipment and operations process leading to millions in dollar savings and avoiding unplanned outages. ECG’s Predict-It software suite provides digital twin or quantitative equipment models in its real-time process environment. The Predict-It models are used to monitor changes over time that are many times undetectable initially by users. This comparative monitoring capability gives Predict-It the ability to report acceptable states of operation and also makes evident early “drift” from these acceptable states of operation. This early warning capability supports a proactive management strategy and intervention before an unplanned outage or asset failure occurs. ECG’s models are effective and a key differentiator in the market because of ECG’s proprietary data imputation method.
To train a Predictive Maintenance model, ECG knew it needed a data imputation method that is accurate, tried, and true. In ECG’s data imputation journey, the team used a multi-stage, continuous improvement selection approach. The process started by subjecting diverse datasets from multiple equipment types to a series of chosen algorithms, which resulted in KNN, PPCA, and MICE emerging as the most effective performers. The results were decent but not at the level of accuracy the team was aiming for. So the Team then took the worst-case scenario dataset which included data that had roughly 75% missing data, a small sample size, or where the correlation of the dataset was extremely nonlinear, and tested them through the three methods again. As a result, MICE was found to be inflexible in many scenarios. KNN was better in most scenarios and PPCA was better in some other areas. To get an algorithm that was able to handle all the different scenarios, the ECG team had many iterations of tweaking and testing of the algorithms. The final version of the algorithm that ECG uses for data imputation is a modified version of the KNN algorithm, which has continuously shown higher accuracy.
Predict-It Examples
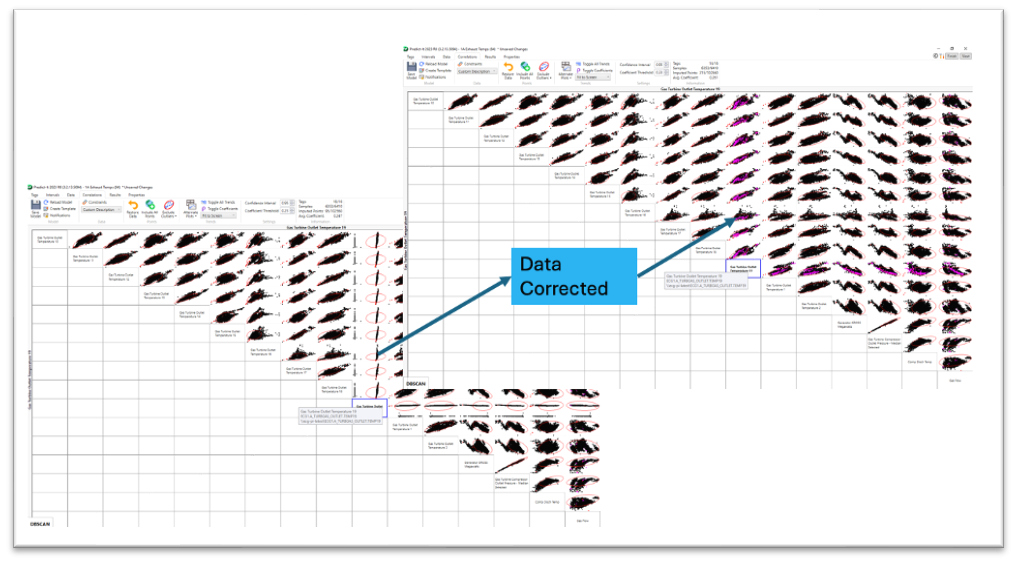
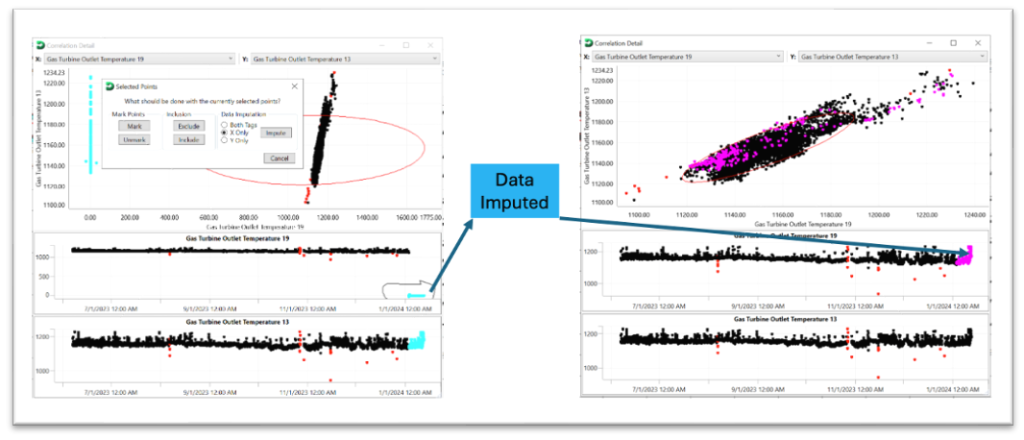
The graphic below depicts Predict-It’s built-in Data Imputation user interface, which allows the user to assess any missing data from the uploaded historical dataset and decide whether to impute the missing data and analyze the imputed results. Once the historical data is uploaded, Predict-It’s data analysis engine will identify all missing data and recommend the optimal data imputation procedure for each variable provided. The proposed algorithm is based on the type of missing data, the volume of missing data, and time-to-compute, so the user is not forced to make a difficult decision. The end user then can impute missing data with the system recommendation, ignore the missing data, or remove the variable from the model entirely. After the data is imputed, the user can review the results and roll back the imputed data for the variable or a specific data point. This gives the user control over the dataset used to build the model and allows local expertise to help shape it.
Image 1: Predict-It Data Imputation User Interface Screen
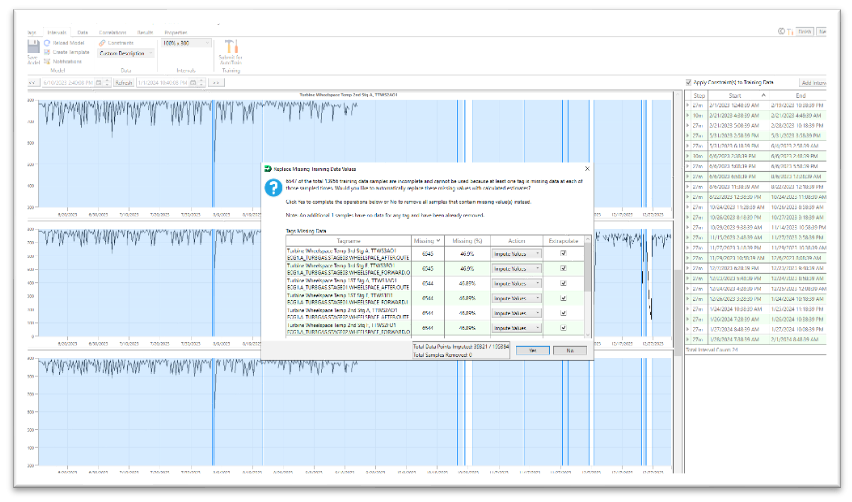
Image 2: Example of Sensor Flatline Area Identified by Predict-It
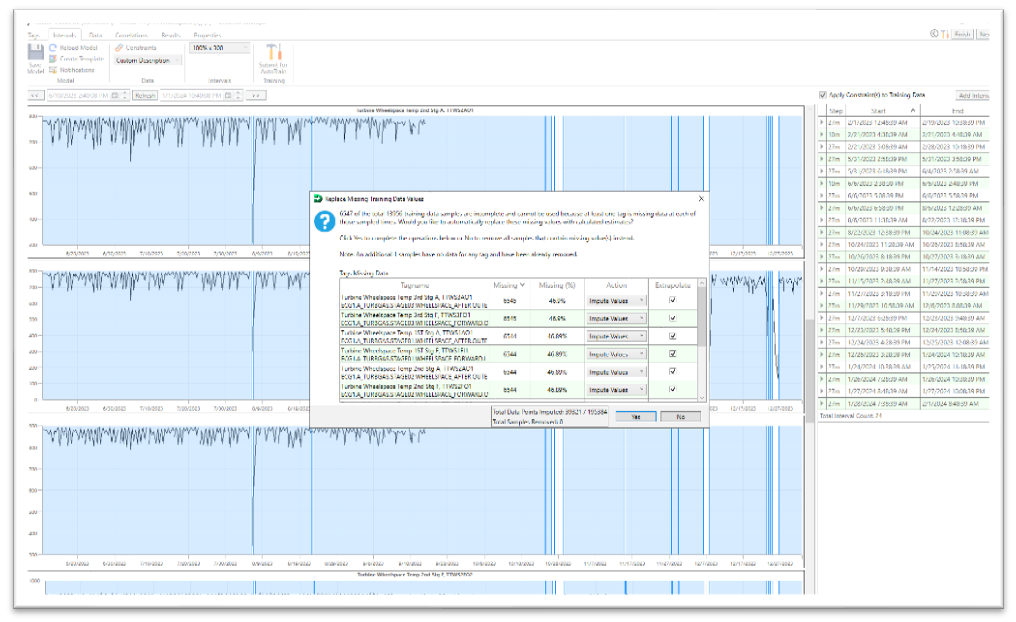
Image 3 & 4: Example Flatlined Data Replaced with Estimates from Data Imputation
Conclusion
In conclusion, data gaps will always exist in digital industrial operations; a solid data imputation model is essential for the success of predictive maintenance strategies. While many data imputation algorithms do a decent job, they aren’t without their own set of restrictions and limitations. Choosing a data imputation algorithm is not always a simple task; it often necessitates a delicate heuristic approach that may involve tweaking and converging multiple approaches together. ECG has undergone this process and has developed a successful data imputation method for its predictive maintenance solution, Predict-It.
For further information or to schedule a demo about Predict-It please contact us at:
ECG – Engineering Consultants Group, Inc.
Phone: +1 330-869-9949
Email: Sales@ecg-inc.com
Website: www.ecg-inc.com